

我們 DotAI 團隊觀察到,Google 於 2026 年 3 月 3 日正式推出 Gemini 3.1 Flash-Lite,定位為 Gemini 3 家族中成本最低、延遲最短的模型。這款模型由旗艦級 Gemini 3 Pro 蒸餾技術 而成,透過先進的模型壓縮技術,它完美繼承了大模型的「智慧」與邏輯能力,同時實現了極速推理與極低營運成本。
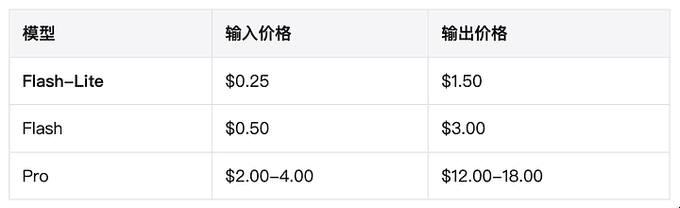
這款由旗艦級 Gemini 3 Pro 蒸餾而成的輕量化版本,定價方面極具競爭力:每百萬輸入 token 收費 0.25 美元(約合港幣 1.95 元),輸出 token 則為 1.5 美元(約合港幣 11.7 元)。相較於同月稍早上市的 Gemini 3 Flash(輸入 0.5 美元、輸出 3 美元,即約港幣 3.9 元及 23.4 元),Flash-Lite 的整體費用僅為後者的一半
👉 官方入口:點此進入 Google AI Studio 實測
4 大核心重點:
壓縮營運成本 → 混合價格約每百萬 Token 0.56 美元,僅為旗艦級模型的八分之一。
提升輸出速度 → 實測輸出高達每秒 388.8 個 Token,較上一代快 45%。
突破基準測試 → GPQA Diamond 測試達 86.9%,在同價位模型中具備統治級表現。
操控思考等級 → 首創 Minimal 到 High 四檔動態推理深度切換,精準控制算力。
拆解 Gemini 3.1 Flash-Lite 4大核心優勢
價格優勢 官方定價降至旗艦模型八分之一
企業在實際部署 AI 時,真正決定基礎設施帳單的往往是這類「效率層(Efficiency Tier)」模型。
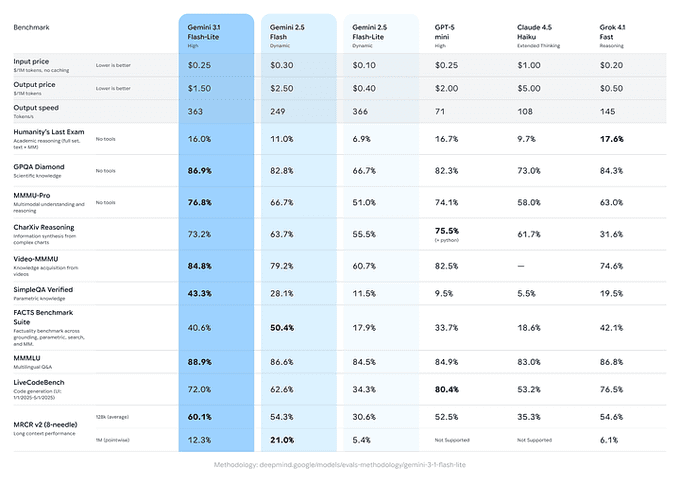
定價: Gemini 3.1 Flash-Lite 定價為每百萬輸入 Token 0.25 美元,輸出 1.50 美元。
混合成本精算: 按照 Artificial Analysis 提供之 3:1 輸入與輸出混合比例計算,實際混合價格約為每百萬 Token 0.56 美元。此成本僅為 3.1 Pro 的八分之一,大幅減輕企業大規模調用 API 的財務負擔。
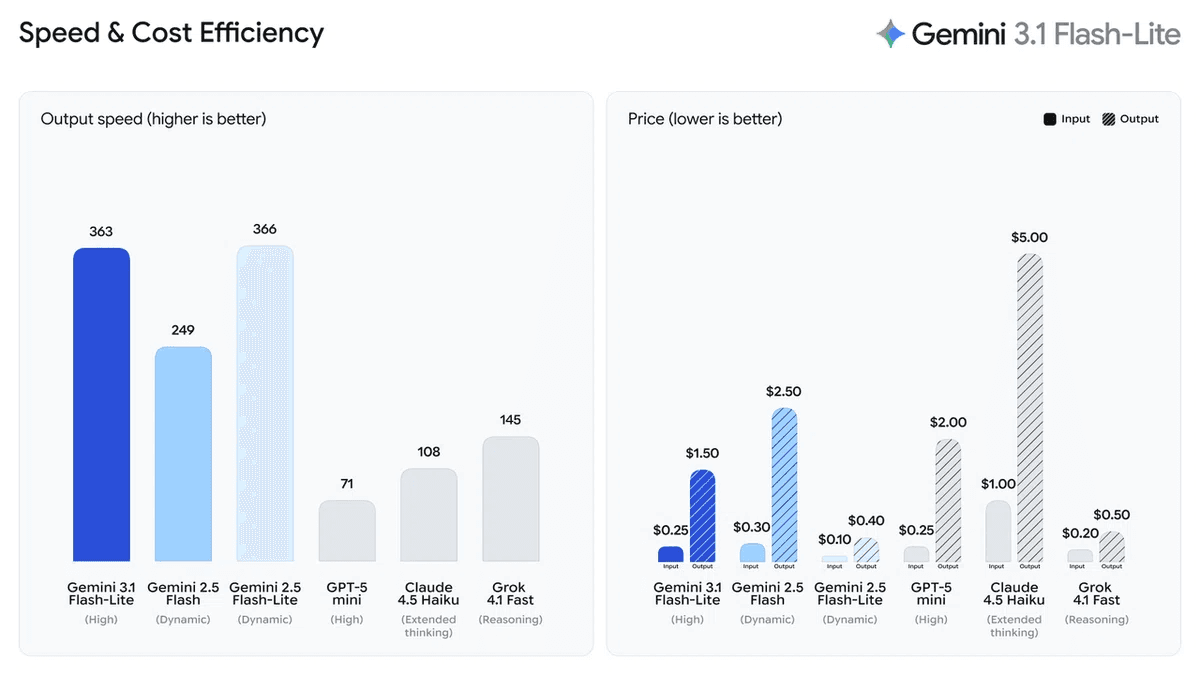
用1/4價格 提升5倍生成速度:高達每秒 388 Token 輸出
對於需要即時回應的高頻工作流,速度即是生產力。Google 透過複雜的工程優化,使模型效能大幅躍升。
生成數據提升: 相比前代 2.5 Flash,首個 Token 響應速度快 2.5 倍,輸出速度實測高達每秒 363 至 388.8 個 Token,位居同級別模型頂尖水準。
客觀局限(避坑注意): 基準測試指出,其首次回應延遲(TTFT)為 5.18 秒,於同價位推理模型中偏高。若企業場景對首 Token 延遲極度敏感,建議從系統層面優化提示詞與思考等級,以強制確保輸出簡潔。
更強推理與多模態理解能力:跑分全面超越同級競品
這絕非單純的「廉價版」,其展現出超越體型的高階實力,免除企業支付不必要的「推理稅」。
多領域權威霸榜: 於 GPQA Diamond 得分 86.9%、MMMU Pro 達 76.8%,Arena.ai 排行榜 Elo 分數高達 1432,全面領先同級對手。
優化結構化工作: 模型特別針對 UI 介面代碼生成、系統模擬以及需要狀態追蹤的 Agent 工作流進行深度優化,確保在長上下文中維持邏輯一致性。
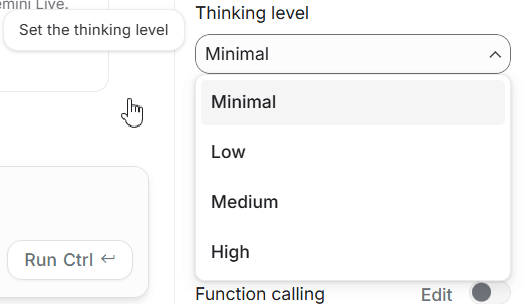
操控 Thinking Levels 等級:四檔切換精準分配算力
作為 3.1 系列最重要的架構更新,模型內建了「思考等級(Thinking Levels)」調整功能,讓開發者能在「延遲」與「邏輯準確度」間取得精確權衡:
最低 / 低(Minimal / Low): 針對翻譯、內容審核等高併發且邏輯簡單之任務。
中(Medium): 適用於多數常規生產任務,完美取得品質與效率平衡。
高(High): 針對生成使用者介面或執行複雜指令等任務,啟動高階推理能力。
盤點4大商業應用場景實測
案例一:上架電商產品信息
透過 Gemini 3.1 Flash-Lite 強大的生成能力,企業能瞬間為複雜的網頁框架填充數百件商品資訊。這不僅涵蓋自動化的類別歸納與標籤設定,更能根據產品特性產出精準的描述與規格屬性。對於擁有龐大庫存單位(SKU)的電商平台而言,這項技術將原本需耗時數天的手動錄入工作縮短至秒級完成,大幅降低了人力成本,讓產品得以第一時間面世。
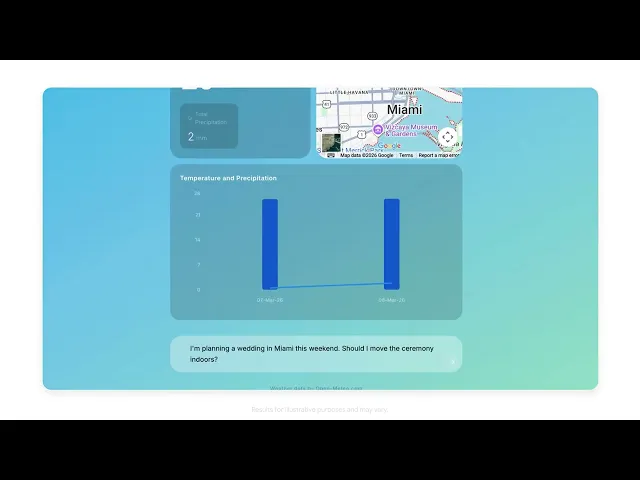
案例二:即時數據可視化
藉由整合即時預測與海量歷史資料,Gemini 3.1 Flash-Lite 能夠在極短時間內生成動態數據儀表板(Dynamic Dashboard)。無論是氣象預測分析還是業務績效監控,該模型都能將冰冷的原始數據轉化為直觀的視覺化指標。這種高效的實時運算反饋,使決策者能隨時掌握業務脈動,並依據 AI 提供的精準洞察調整戰略,實現真正的數據驅動管理。
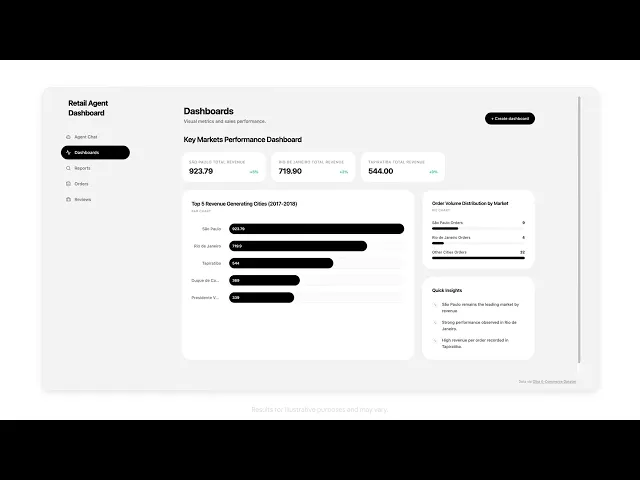
案例三:處理行政雜務
這類智慧代理人具備執行跨平台、多步驟複雜任務的推理能力,能自動處理報價單生成、客戶進度跟進及各項行政審核流程。透過將企業的標準作業程序(SOP)封裝進 AI 模型中,企業能以極低的運作成本建立一套全天候運作的工作流,不僅有效解決人力短缺的問題,更讓團隊能專注於更具策略價值的核心業務。
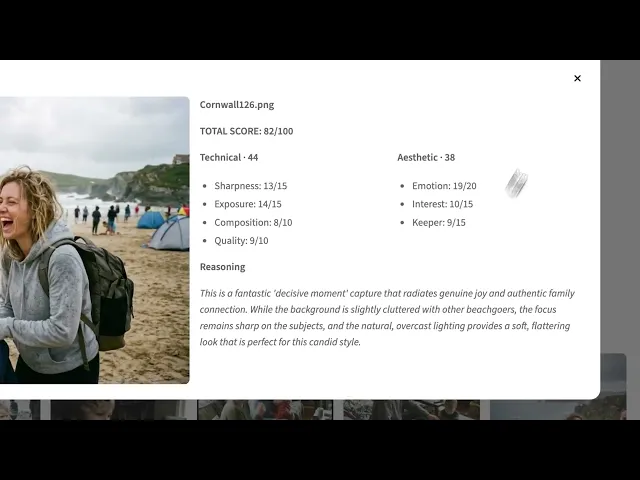
案例四:圖像資產整理
Gemini 3.1 Flash-Lite 憑藉卓越的多模態視覺分析能力,能極速識別並歸類成千上萬張數位素材。透過深入分析內容特徵,AI 能自動為每項資產建立精準的標籤索引,讓團隊徹底告別漫長的手動整理過程。這項技術不僅顯著提升了素材的調用效率,更確保企業的數位資產能得到最有效的開發與利用,強化整體的品牌競爭力。
Gemini 3.1 Flash-Lite常見問題 (FAQ)
Q1:香港用戶目前如何存取?有沒有訂閱帳號限制?
無須訂閱特定的月費方案(如 Gemini Advanced)。 目前 Gemini 3.1 Flash-Lite 是針對開發者與企業推出的 API 模型,採 Pay-as-you-go(按使用量計費)模式。香港用戶可透過企業級雲端平台 Vertex AI 部署,或直接進入 Google AI Studio 存取預覽版(註:於 AI Studio 測試時,部分香港網路環境可能需要 VPN 輔助)。
Q2:企業應如何選擇 Gemini 3.1 Flash-Lite 與 2.5 Flash?
若企業需要處理極高頻率、對速度要求極高(如實時翻譯、海量數據過濾)的任務,建議過渡至 3.1 版本以獲取快 2.5 倍的反應速度與思考等級功能;若現有系統已穩定運行於 2.5 Flash 且無極端速度需求,則可維持現狀。
Q3:啟動「高」思考等級會否大幅增加 API 費用?
調高思考等級會讓模型生成更多「推理 Token」,進而增加單次輸出成本。然而,相比呼叫定價高出八倍的旗艦級 3.1 Pro 模型,使用 Gemini 3.1 Flash-Lite 的高階模式依然具備顯著成本優勢。
Google 與 OpenAI 競爭格局,確立「大規模執行」優勢
Gemini 3.1 Flash-Lite 的發佈時間點極具戰略意味。在同一天,OpenAI 亦推出了 GPT-5.3 Instant。雖然兩大巨頭同時出招,但技術演進的方向卻截然不同:OpenAI 專注於優化現有模型的使用者體驗(如降低幻覺率與修正語氣),而 Google 則透過全新的 Flash-Lite 輕量模型,精準瞄準企業端「大規模部署」與「高頻率應用」的痛點。
盤點目前的輕量模型市場,Flash-Lite 的直接競爭對手涵蓋了 OpenAI 的 GPT-5 mini、Anthropic 的 Claude 4.5 Haiku 以及 xAI 的 Grok 4.1 Fast。Google 此次透過同步提供 Gemini 3.1 Pro(負責深度推理的「企業大腦」)與 3.1 Flash-Lite(負責極速回應的「反射神經」),向市場傳達了一個極其明確的信號:
AI 商業競賽的下一階段,企業不僅要具備「深度思考」的能力,更必須擁有「大規模執行」的系統。
立即行動 建構你的AI自動化生產力
在 2026 年,技術門檻已經不再是阻礙。Gemini 3.1 Flash-Lite 的出現證明了一件事:未來的 AI 競爭不只是比大模型厲害程度,而是比誰的SOP更順暢。DotAI No-Code 商業應用班 跳過艱澀的程式碼,直接帶你用最直覺的 No-Code 工具,將 Gemini 3.1 的極速效能轉化為自動化生產力。
兩大實戰模組,全方位武裝你的 AI 技能:
Lv.1 AI x No-Code 網站與 APP 快速構建: 利用 v0 AI 技術,將你的商業靈感「講」給 AI 聽,即時生成專業級的 UI 介面與功能齊全的網頁原型。無論是 Landing Page 還是內部管理系統,唔使寫一行 Code,幾分鐘內就能將想法變現。
Lv.2 AI Agent 大師班:商用級自動化工作流: 這是我們最核心的實戰單元。我們會教你如何透過 Dify 或 n8n 等平台,將 Gemini 3.1 Flash-Lite 串接到你的 WhatsApp、Email 或 CRM 系統。你將親手搭建出能夠自動分析數據、處理工單、追蹤訂單的 AI 智能體(Agent),真正實現「瞓覺都有 AI 幫你做嘢」。
為什麼選 DotAI? 我們不講理論,只講落地。10 小時的時間,我們帶你避開所有 API 踩坑位,直接掌握 2026 年最強的 AI 工具組合。在這個「快魚食慢魚」的時代,掌握 No-Code 技術,你就能用 1/4 的成本,跑出競爭對手 5 倍的速度!
👉立即點擊這裡報名,加入 DotAI No-Code 實戰班

DotAI Spot
AI 實戰成長社群
DotAI 全新學習體驗,陪伴您跨越 AI 學習迷惘




其他文章











