

AI 配音終於學會「呼吸」了?
我們 DotAI 團隊觀察到,MiniMax Audio最新釋出的 Speech 2.8 語音生成模型,這不只是一次例行更新,而是 AI 語音技術的一次重要「質變」。過往我們使用文字轉語音工具,最擔心的就是那種平鋪直敘、毫無起伏的「Siri 感」。但 Speech 2.8 引入了 Sound Tag (音效標籤) 與更細膩的 Emotion (情緒控制),讓 AI 終於學會了嘆氣、大笑,甚至在說話間隙「呼吸」。這意味著,大家現在可以用免費的額度,生成出足以媲美真人廣播劇的配音素材。
MiniMax Speech 2.8 官方入口: https://www.minimax.io/audio
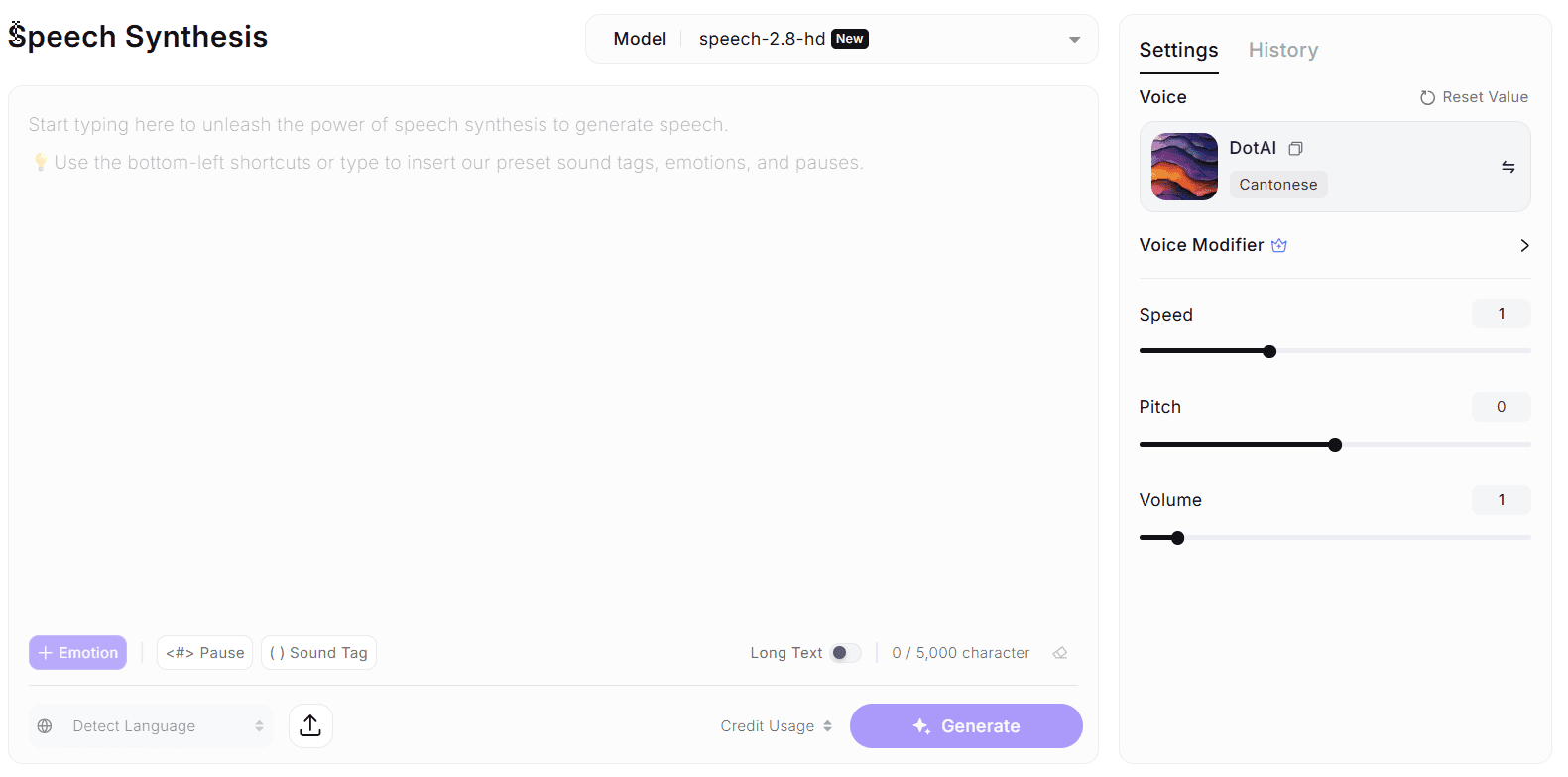
DotAI 觀點 :從「讀稿機」到「實力派演員」
為什麼我們說 Speech 2.8 是「告別機械音」的關鍵?
傳統的 AI 配音工具,就像一個「盡責的新聞主播」,字正腔圓,但永遠只有一種語調。無論你寫的是悲劇還是喜劇,它讀起來都像在報天氣。
而 MiniMax Speech 2.8 的邏輯,則更像是一位「進了錄音室的專業聲優」。它不再只是單純地把文字讀出來,而是具備了「理解語氣」的能力:
拒絕一條平線:傳統 AI 的情緒是全域設定(整段都開心或整段都悲傷),Speech 2.8 容許你 逐句微調 (Fine-tune each sentence)。就像導演說戲一樣,你可以要求它「這句要笑著說,下一句要無奈地嘆氣」。
注入非語言細節:人類說話時會有停頓、吸氣、清喉嚨等聲音。Speech 2.8 的 Sound Tag 功能,正是補足了這些以往被 AI 忽略的「人性細節」,讓聲音聽起來有血有肉。

核心功能實測3 步注入靈魂:Emotion、Pause 與 Sound Tag 操作全攻略
DotAI 團隊實測後發現,要讓 MiniMax 生成的聲音從「像人」變成「是人」,關鍵在於善用 Speech 2.8 新增的三大控制工具。以下是我們總結出的「注入靈魂」三部曲 :
1. 加入環境音效 用 Sound Tag 製造「臨場感」
以往 AI 配音最不自然的地方,就是聲音「太乾淨」。真人說話時會有氣聲、笑聲甚至清喉嚨的聲音。Speech 2.8 的 Sound Tag (音效標籤) 功能,就像在文字訊息中加入 Emoji 一樣簡單,直接將「動作」插入語音中。
操作方法:在輸入框打字時,點擊「Sound Tag」按鈕,選擇對應標籤(例如 [laugh] 笑聲、[breath] 呼吸聲)。
實測效果:
輸入:「DotAI 職場 AI 技能速成班推薦比所有打工仔![laugh] 12 小時學晒 AI 職場技能,從 AI PPT、自動化報告、AI 會議紀錄、個人 AI 助手,一次過學晒!,打工變得更 Smart,準時收工無難度!」
結果:AI 會在說完「DotAI 職場 AI 技能速成班推薦比所有打工仔!」後,自然地發出笑聲,再接著說下一句,整體的語氣瞬間變得生動自然。

2. 掌控說話節奏 用 Pause 設定「呼吸位」
說話沒有停頓,聽眾很快會感到疲憊。Pause 功能讓你精準控制句子與句子之間的「留白」時間。
操作方法:將游標放在想停頓的位置,點擊「Pause」。你可以使用預設時長(如 0.5s),或者手動輸入數值(例如 2.0s 用於營造緊張氣氛)。
應用場景:
埋下期待值:2026年如果想學AI融入marketer,我可以點做?【1秒】DotAI既AI Marketing 營銷特訓班相信幫到你,AI 內容生成、SEO、 AI圖像設計、 Canva、廣告貼文、自動化行銷,從 策略到落地,一次學晒! 用輕鬆吸客 x10!【1.35秒】

3. 拒絕平鋪直敘 用 Emotion 逐句「調校」語氣
這是 Speech 2.8 最強大的地方。傳統 TTS 設定完「開心」就整段都開心,但 Speech 2.8 支援 Sentence-Level Emotion (逐句情感控制)。
操作方法:選取想調整的句子,點擊「Emotion」,然後在選單選擇情緒(如 Happy 開心、Sad 悲傷、Angry 憤怒),還可以調整強度拉桿 (Intensity Bar) 微調強弱。
DotAI 實戰示範:
第一句(設定 sad):「這個月的業績很差...」(聲音低沉、帶點哽咽)
第二句(設定 surprised):「因為你唔識set AI agent 24小時幫你對客,DotAI既AI Agent + No-Code 商業 AI 實戰班,實現0寫 Code基礎,整網站+應用程式、AI Agent 自動化,即學即用!」(聲音充滿希望)
結果:透過這種反差,你可以輕易製作出有起承轉合的廣播劇或 Storytelling 旁白 。

獨家黑科技|Voice Design:用文字「設計」出獨一無二的聲音
如果你厭倦了千篇一律的「罐頭配音」,MiniMax 的 Voice Design (聲音設計) 功能將是你的救星。它就像聲音界的 Midjourney,你只需要輸入文字描述,AI 就能憑空「畫」出一段全新的聲音 。
AI像編劇一樣描述角色
你不再需要從聲音庫中大海撈針,只需將你腦海中的角色形象描述出來 。
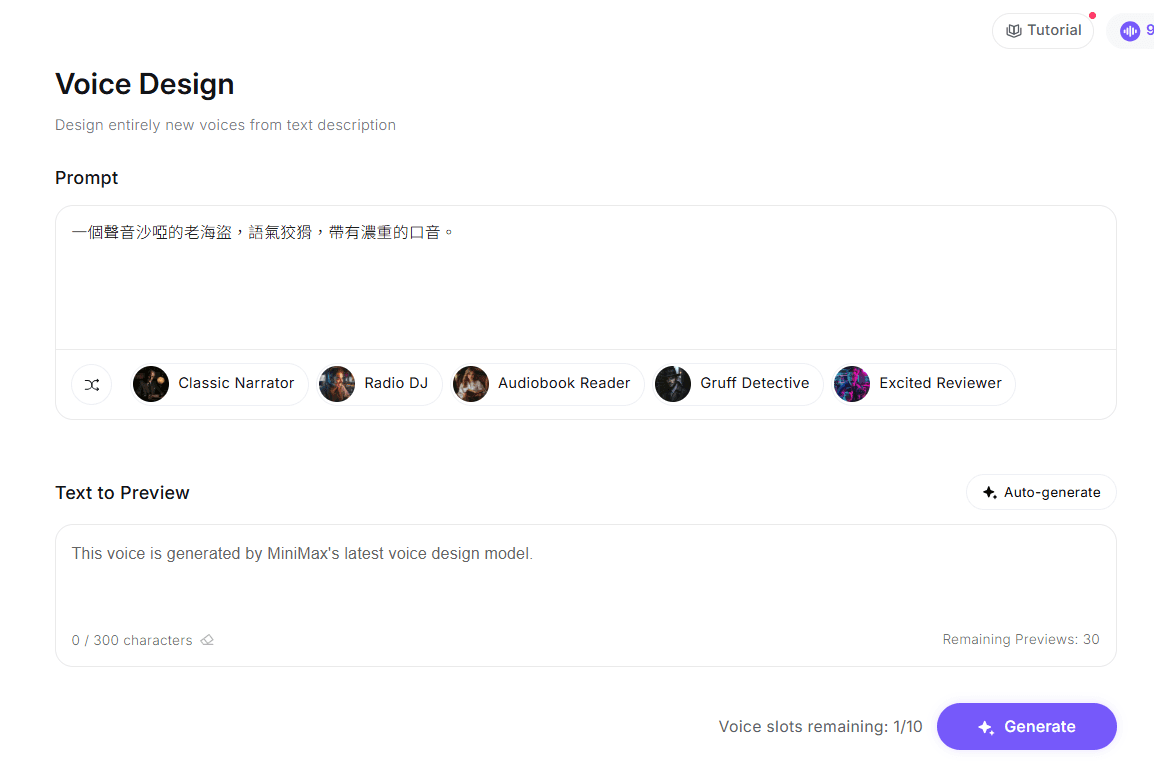
操作方法:在 Voice Design 介面輸入描述 (Prompt)。或許是參考內置的聲音風格再參考,可以選擇專業旁白、DJ等

DotAI 實測 Prompt:
「一個聲音沙啞的老海盜,語氣狡猾,帶有濃重的口音。」
「一位溫柔的幼稚園女老師,說話輕聲細語,充滿耐心。」
結果:AI 會根據這些形容詞,會生成三個聲音,大家可以選擇最符合你需求的聲音
100% 原創,解決版權痛點
對於內容創作者來說,Voice Design 最大的價值在於「原創性」。因為這些聲音是由 AI 根據描述生成的,並非複製特定的真人聲音 (Voice Cloning),因此能有效避免撞聲或潛在的肖像權爭議,非常適合用於開發遊戲 NPC、虛擬角色或品牌專屬旁白。
總結 AI 配音工具首選
在強大的 Speech 2.8 模型與 Voice Design 功能背後,MiniMax Audio 同時堅持實惠且易於使用的定價策略,致力於降低創作者的使用門檻 。
為什麼選擇 MiniMax Audio?
每月免費額度:所有用戶每月均享有 10,000 Credits 的免費額度,足以應付日常短片創作、測試或個人專案需求。
免費聲音複製 (Voice Cloning):首次使用者即獲贈 3 個免費 Voice Cloning 額度。相比於市場上其他主流工具(如 ElevenLabs 通常需付費訂閱才能解鎖此功能),MiniMax 對新手更加友善。
更具競爭力的價格:若您有更高用量的商業需求,MiniMax 的付費方案價格比同類工具(如 ElevenLabs)便宜約 25%,讓您在擴大創作規模時大幅節省成本。
DotAI Spot
AI 實戰成長社群
DotAI 全新學習體驗,陪伴您跨越 AI 學習迷惘




其他文章











