
23 年 11 月 8 日,新加坡政府科技局(GovTech)組織舉辦了首屆 GPT-4 提示工程(Prompt Engineering)競賽。數據科學家 Sheila Teo 最終奪冠。之後,Sheila 發布了一篇題為《How I Won Singapore’s GPT-4 Prompt Engineering Competition》的文章,分享她的創作思路。
DotAI 對這篇可以大大提升文章寫 Prompt 能力的文章進行的翻譯與整理,幫大家一齊成為 LLM 指令高手。
AI 指令教學《How I Won Singapore’s GPT-4 Prompt Engineering Competition》正文
上個月,我非常榮幸地贏得了新加坡首屆 GPT-4 提示工程競賽;該競賽由新加坡政府科技局組織,匯集了 400 多名優秀的參賽者。
提示工程是一門融合了藝術與科學的學科 —— 它既需要對科技的理解,也需要創造力和策略思維。這篇文章彙編了我一路學習到的提示工程策略,這些策略能讓 LLM 切實完成你想完成的任務並做到更多!
作者註:寫作本文時,我試圖擺脫已在網路上被廣泛討論和整理成文件的傳統提示工程技術。相反,我的目標是分享我透過實驗學習到的新見解以及對理解和處理某些技術的一些不同的個人看法。希望你會喜歡這篇文章!
本文包含以下內容,其中 🔵 是指適合初學者的提示工程技術,而 🔴 是指進階技術。
- [🔵] 使用 CO-STAR 框架來建構 prompt 的結構
- [🔵] 使用分隔符號為 prompt 設定分節
- [🔴] 使用 LLM 防護圍籬創建系統 prompt
- [🔴] 僅使用 LLM 分析資料集,不使用外掛程式或程式碼 —— 附帶一個實操範例:使用 GPT-4 分析一個真實的 Kaggle 資料集。
1. [🔵] 使用 CO-STAR 框架來建構 prompt 的結構
為了讓 LLM 給予最優響應,為 prompt 設定有效的結構至關重要。 CO-STAR 框架是一種可以方便用於設計 prompt 結構的模板,這是新加坡政府科技局的資料科學與 AI 團隊的創意成果。此範本考慮了會影響 LLM 回應的有效性和相關性的方方面面,從而有助於得到更優的回應。
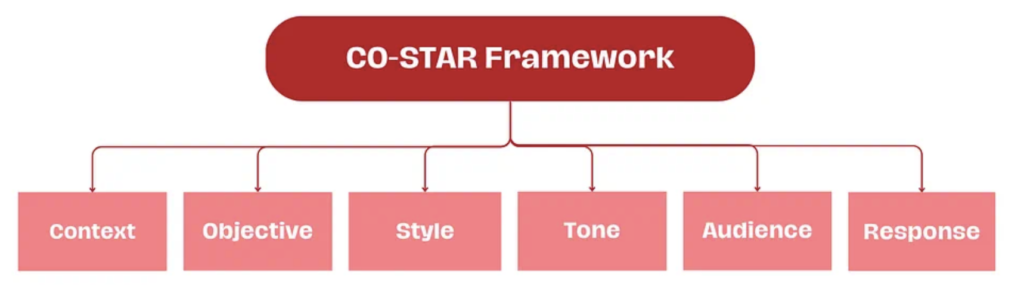
其工作方式為:
(C) 上下文(Context):提供與任務有關的背景資訊。這有助於 LLM 理解正在討論的具體場景,從而確保其反應是相關的。
(O) 目標(Objective):定義你希望 LLM 執行的任務。明晰目標有助於 LLM 將自己回應重點放在完成具體任務上。
(S) 風格(Style):指定你希望 LLM 使用的寫作風格。這可能是一位具體名人的寫作風格,也可以是某種職業專家(如商業分析師或 CEO)的風格。這能引導 LLM 使用符合你需求的方式和字詞給予回應。
(T) 語氣(Tone):設定回應的態度。這能確保 LLM 的回應符合所需的情感或情緒上下文,例如正式、幽默、善解人意等。
(A) 受眾(Audience):確定回應的目標受眾。針對特定受眾(如領域專家、初學者、孩童)客製化 LLM 的回應,確保其在你所需的上下文中是適當的和可被理解的。
(R) 回應(Response):提供回應的格式。這能確保 LLM 輸出你的下游任務所需的格式,例如清單、JSON、專業報告等。對於大多數透過程式化方法將 LLM 回應用於下游任務的 LLM 應用而言,理想的輸出格式是 JSON。
CO-STAR 的一個實際應用
這裡透過一個實際案例說明 CO-STAR 為什麼有用。假設你是一位社群媒體管理者,你需要幫助草擬一篇 Facebook 帖文,其內容是宣傳你公司的新產品。
如果不使用 CO-STAR,那麼你可能會使用這樣的 prompt:
Write a facebook post to advertise my company’s new product. My company’s name is Alpha and the product is called Beta, a new ultra-fast hairdryer.
GPT-4 的輸出如下:
Introducing the Revolutionary Beta Hairdryer by Alpha!
– Say goodbye to long, tedious hair drying sessions! Alpha is proud to unveil the Beta, our latest innovation in haircare technology.
– Ultra-Fast Drying: The Beta is designed to cut your drying time in half, thanks to its advanced, powerful motor. Get ready faster and enjoy more time doing what you love!
Shop Now: [Link to product page]
這個結果也許夠用了,但卻只是泛泛而談,缺乏具體的細節和有針對性的吸引力,而這些是吸引目標受眾所必需的。
那如果使用 CO-STAR 模板呢? CO-STAR 會提醒你將任務涉及的其它方面也整合進 prompt 之中,具體來說就是上面的簡單 prompt 中缺少的 STYLE、TONE、AUDIENCE 方面:
# CONTEXT #I want to advertise my company’s new product. My company’s name is Alpha and the product is called Beta, which is a new ultra-fast hairdryer.# OBJECTIVE #Create a Facebook post for me, which aims to get people to click on the product link to purchase it.
# STYLE #Follow the writing style of successful companies that advertise similar products, such as Dyson.# TONE #Persuasive
# AUDIENCE #My company’s audience profile on Facebook is typically the older generation. Tailor your post to target what this audience typically looks out for in hair products.# RESPONSE #The Facebook post, kept concise yet impactful.
透過使用 CO-STAR,GPT-4 的反應會變得明顯更有針對性、效果更好:
Embrace Effortless Elegance with Alpha Beta — The Ultra-Fast Hairdryer for the Wise Generation.
Rediscover the joy of simple, effective hair care with Alpha Beta. Our latest innovation is more than just a hairdryer; it’s a promise of swift, gentle, and reliable hair styling for those who appreciate the finer things in life.
– Easy and Intuitive Use: Say goodbye to complicated gadgets. Alpha Beta iscrafted for comfort and simplicity, perfect for those who value straightforward,hassle-free technology.
– Time-Saving Technology: We understand your time is precious. That’s why Alpha Beta cuts down drying time significantly, giving you more moments to enjoy life’s pleasures.
Make every day a good hair day with Alpha Beta. Experience the blend of sophistication and simplicity today.[Your Product Link Here]
CO-STAR 框架能引導使用者以一種結構化的方式向 LLM 提供有關你的任務所有關鍵信息,從而確保得到完全符合你的需求的定制化的更優的響應。
2. [🔵] 使用分隔符號為 prompt 設定分節
分隔符號是一種特殊 token,可幫助 LLM 分辨 prompt 的哪些部分應被視為單一意義單元。這很重要,因為輸入 LLM 的整個 prompt 是單一的 token 長序列。分隔符號能將 prompt 中不同部分隔離開,從而為這個 token 序列提供結構,讓其中各個部分能被區別對待。
需要說明的是,如果任務很簡單,那麼分隔符號對 LLM 的反應品質的影響不大。但是,任務越複雜,使用分隔符號分節對 LLM 回應的影響就越大。
用特殊字元當分隔符
分隔符號可以使用任何通常不會同時出現的特殊字元序列,並舉些例子:###、===、>>>
特殊字元的數量和類型並不重要,只要它們足夠獨特即可,這樣才能讓 LLM 將它們理解成內容分隔符,而不是普通的標點符號。
下面透過一個範例說明如何在 prompt 中使用分隔符號:
Classify the sentiment of each conversation in <<<CONVERSATIONS>>> as‘Positive’ or ‘Negative’. Give the sentiment classifications without any other preamble text.
###EXAMPLE CONVERSATIONS[Agent]: Good morning, how can I assist you today?[Customer]: This product is terrible, nothing like what was advertised![Customer]: I’m extremely disappointed and expect a full refund.[Agent]: Good morning, how can I help you today?
[Customer]: Hi, I just wanted to say that I’m really impressed with yourproduct. It exceeded my expectations!EXAMPLE OUTPUTSNegativePositive###<<<
[Agent]: Hello! Welcome to our support. How can I help you today?[Customer]: Hi there! I just wanted to let you know I received my order, andit’s fantastic![Agent]: That’s great to hear! We’re thrilled you’re happy with your purchase.Is there anything else I can assist you with?
[Customer]: No, that’s it. Just wanted to give some positive feedback. Thanksfor your excellent service![Agent]: Hello, thank you for reaching out. How can I assist you today?[Customer]: I’m very disappointed with my recent purchase. It’s not what I expected at all.
[Agent]: I’m sorry to hear that. Could you please provide more details so I can help?[Customer]: The product is of poor quality and it arrived late. I’m reallyunhappy with this experience.>>>
上述範例中使用的分隔符號是 ###,同時每一節都帶有完全大寫的標題以示區分,如 EXAMPLE CONVERSATIONS 和 EXAMPLE OUTPUTS。前置說明部分陳述了要分類的對話是在<<>> 中,這些對話是在prompt 末尾提供,也不帶任何解釋說明文本,但由於有了<<< 和>>> 這樣的分隔符,LLM 就能理解這就是要分類的對話。
GPT-4 對此 prompt 給出的輸出如下,其給出的情感分類結果不帶任何附加文本,這符合我們的要求:
Positive / Negative
用 XML 標籤當分隔符
另一種方法是使用 XML 標籤作為分隔符號。 XML 標籤是使用尖括號括起來的成對標籤,包括開始和結束標籤。如 和 。這很有效,因為 LLM 在訓練時就看過了大量以 XML 標註的網路內容,已經學會了理解其格式。
下面用 XML 標籤來重寫上面的 prompt:
Classify the sentiment of the following conversations into one of two classes, using the examples given. Give the sentiment classifications without any other
preamble text.Positive Negative
[Agent]: Good morning, how can I assist you today?
[Customer]: This product is terrible, nothing like what was advertised!
[Customer]: I’m extremely disappointed and expect a full refund.
[Agent]: Good morning, how can I help you today?[Customer]: Hi, I just wanted to say that I’m really impressed with your
product. It exceeded my expectations!Negative
Positive[Agent]: Hello! Welcome to our support. How can I help you today?
[Customer]: Hi there! I just wanted to let you know I received my order, and
it’s fantastic!
[Agent]: That’s great to hear! We’re thrilled you’re happy with your purchase.
Is there anything else I can assist you with?[Customer]: No, that’s it. Just wanted to give some positive feedback. Thanks
for your excellent service!
[Agent]: Hello, thank you for reaching out. How can I assist you today?
[Customer]: I’m very disappointed with my recent purchase. It’s not what I
expected at all.[Agent]: I’m sorry to hear that. Could you please provide more details so I
can help?
[Customer]: The product is of poor quality and it arrived late. I’m really
unhappy with this experience.
為了達到更好的效果,在 XML 標籤中使用的名詞應該與指令中用來描述它們的名詞一樣。在上面的 prompt 中,我們給的指令為:
Classify the sentiment of the following conversations into one of two classes, using the examples given. Give the sentiment classifications without any other preamble text.
其中使用的名詞有 conversations、classes 和 examples。也因此,後面的分隔 XML 標籤就對應為 、、 和 。這能確保 LLM 理解指令與 XML 標籤的關聯。
同樣的,使用這樣的分隔符能以清晰的結構化方式對 prompt 進行分節,從而確保 GPT-4 輸出的內容就剛好是你想要的結果:
Positive/Negative
3. [🔴] 使用 LLM 防護圍欄創建系統提示
在深入之前,需要指出這一節的內容僅適用於具有 System Prompt(系統提示)功能的 LLM,而本文其它章節的內容卻適用於任意 LLM。當然,具有此功能的最著名 LLM 是 ChatGPT,因此這一節將使用 ChatGPT 作為範例進行說明。
與 System Prompts 有關的術語
首先,我們先把術語搞清楚:對於 ChatGPT,有大量資源使用 System Prompts、System Messages 和 Custom Instructions 這三個術語,而且很多時候它們的意思似乎差不多。這給了許多人(包括我)困擾,以至於讓 OpenAI 都特別發了一篇文章來解釋這些它們。簡單總結一下:
System Prompts 和 System Messages 是透過 ChatGPT 的 Chat Completions API 以程式化方式使用該 LLM 時使用的術語。
另一方面,Custom Instructions 是透過 https://chat.openai.com/ 的使用者介面使用 ChatGPT 時的術語。
不過整體而言,這三個術語指涉的是同一對象,因此請不要過度糾結於此!我們這一節將使用 System Prompts 這個術語。現在就繼續深入吧!
System Prompts 是什麼?
System Prompts 是指附加的額外 prompt,其作用是指示 LLM 理應的行為方式。之所以說這是額外附加的,是因為它位於「普通」prompt(也被稱為用戶 prompt)之外。
在一組聊天中,每次你都要提供一個新的 prompt,System Prompts 的作用就像是一個 LLM 會自動套用的過濾器。這意味著,在一組聊天中,LLM 每次回應都要考慮 System Prompts。
應在何時使用 System Prompts?
你腦袋冒出的第一個問題可能是:我為什麼應該在 System Prompts 中提供指令,畢竟我可以在一組聊天的第一個 prompt 中提供這些指令?
答案是因為 LLM 的對話記憶有限制。如果在一組對話的第一個 prompt 中提供這些指令,隨著對話的進行,LLM 可能會「遺忘」你提供的第一個 prompt,其中的指令也就失效了。
另一方面,如果在 System Prompts 中提供這些指令,那麼 LLM 就會自動將其與新的 prompt 一起納入考慮。這能確保隨著對話進行,LLM 能持續接收這些指令,無論聊天變得多長。
總結一下:使用 System Prompts 提供你希望 LLM 在整個聊天過程中全程記住的指令。
System Prompts 應包含什麼內容?
System Prompts 中的指令通常包含以下類別:
任務定義,這樣 LLM 在聊天過程中能一直記得要做什麼。
輸出格式,這樣 LLM 能一直記得自己該如何回應。
防護圍欄,讓 LLM 一直記得自己不該如何回應。防護圍欄(Guardrails)是 LLM 治理方面一個新興領域,是指為 LLM 配置的可運作操作的邊界。
舉個例子,System Prompt 可能是這樣的:
You will answer questions using this text: [insert text].You will respond with a JSON object in this format: {“Question”: “Answer”}.If the text does not contain sufficient information to answer the question, do not make up information and give the answer as “NA”.
You are only allowed to answer questions related to [insert scope]. Never answer any questions related to demographic information such as age, gender, and religion.
其中每部分的類別如下:

那麼「普通」prompt 又該包含哪些內容呢?
現在你可能會想:看起來 System Prompt 中已經給了大量資訊。那我們又該在「普通」prompt(也稱為使用者 prompt)中放什麼內容呢?
System Prompt 會大致描述任務概況。在上面的 System Prompt 範例中,任務被定義為僅使用特定的文字進行問答,並指示 LLM 以 {“Question”: “Answer”} 的格式進行回應。
You will answer questions using this text: [insert text].
You will respond with a JSON object in this format: {“Question”: “Answer”}.
在這個案例中,聊天中的每個使用者 prompt 都只是你希望得到文字解答的問題。舉個例子,使用者 prompt 可能是這樣「What is the text about?」。而 LLM 的回應會是這樣:{“What is the text about?”: “The text is about…”}。
但我們可以進一步泛化這個範例任務。在實踐中,你更可能會有多個希望得到解答的問題,而不只是一個。在這個案例中,我們可以將上述 System Prompt 的第一行從
You will answer questions using this text: [insert text].
改成
You will answer questions using the provided text.
現在,每個使用者 prompt 中都既包含執行問答所基於的文本,也包含所要回答的問題。
<text>
[insert text]
</text>
<question>
[insert question]
</question>
這裡,我們依然使用 XML 標籤作為分隔符,以一種結構化的方式為 LLM 提供這兩段所需資訊。此處 XML 標籤中使用的名詞是 text 和 question,對應於 System Prompt 中使用的名詞,這樣一來 LLM 就能理解這些標籤與 System Prompt 指令有何關聯。
總結起來,System Prompt 應該可以給予整體的任務指令,而每個使用者 prompt 應提供你希望執行任務時使用的確切細節。例如在這個案例中,這個確切的細節是文字和問題。
附加:讓 LLM 防護圍籬變得動態化
在上面,防護圍欄是透過 System Prompt 中的幾句話添加的。然後,這些防護圍欄在聊天的整個過程中就不變了。那如果你希望在對話的不同位置使用不同的防護圍欄呢?
不幸的是,對於 ChatGPT 用戶介面的用戶,目前還沒有能做到這一點的簡單方法。但是,如果你透過程式設計方法與 ChatGPT 交互,你就很幸運了!現在人們對建造有效的 LLM 防護圍欄的興趣越來越大,有研究者開發了一些開源軟體包,可讓用戶能以程式設計方式設定遠遠更加細節和動態的防護圍欄。
英偉達團隊開發的 NeMo Guardrails 尤其值得注意,這能讓使用者配置與 LLM 之間的期望對話流,從而在聊天的不同位置設置不同的防護圍欄,實現隨聊天不斷演進的動態防護圍欄。我強烈建議你研究一下!
4. [🔴] 僅使用 LLM 分析資料集,不使用外掛程式或程式碼
你可能聽過 OpenAI 為 GPT-4 版本的 ChatGPT 提供的 Advanced Data Analysis(進階資料分析)外掛程式 —— 進階(付費使用者)可以使用。這讓使用者可以向 ChatGPT 上傳資料集,然後直接在資料集上執行程式碼,以實現精準的資料分析。
但你知道嗎,其實不使用這樣的插件也能讓 LLM 分析資料集?我們首先了解完全使用 LLM 分析資料集的優點和限制。
LLM 不擅長的資料集分析類型
你可能已經知道,LLM 執行準確數學計算的能力有限,這使得它們不適合需要對資料集進行精確定量分析的任務,例如:
描述性統計數值計算:以量化方式總結數值列,所使用的量測包括平均數或變異數。
相關性分析: 取得列之間的精確相關係數。
統計分析:例如假設測試,可以確定不同資料點分組之間是否有統計上的顯著差異。
機器學習:在資料集上執行預測性建模,可以使用的方法包括線性迴歸、梯度提升樹或神經網路。
正是為了在資料集上執行這樣的定量分析任務,OpenAI 才做了 Advanced Data Analysis 插件,這樣才能藉助程式語言來為這些任務在資料集上執行程式碼。
那麼,為什麼還需要不使用外掛、僅使用 LLM 來分析資料集呢?
LLM 擅長的資料集分析類型
LLM 擅長識別模式和趨勢。這種能力源自於 LLM 訓練時所使用的大量多樣化數據,這讓它們可以識別出可能並不顯而易見的複雜模式。
這讓他們非常適合處理基於模式發現的任務,例如:
異常檢測:基於一列或多列數值識別偏離正常模式的異常資料點。
聚類:基於列之間的相似特徵對資料點進行分組。
跨列關係:識別列之間的綜合趨勢。
文字分析(針對文字為主的列): 基於主題或情緒執行分類。
趨勢分析(針對具有時間屬性的資料集):辨識列之中隨時間演進的模式、季節變化或趨勢。
對於這些類型的模式為基礎的任務,實際上比起使用程式碼,僅使用 LLM 可能還能在更短的時間內得到更好的結果。下面透過一個範例來完整示範一番。
僅使用 LLM 來分析 Kaggle 資料集
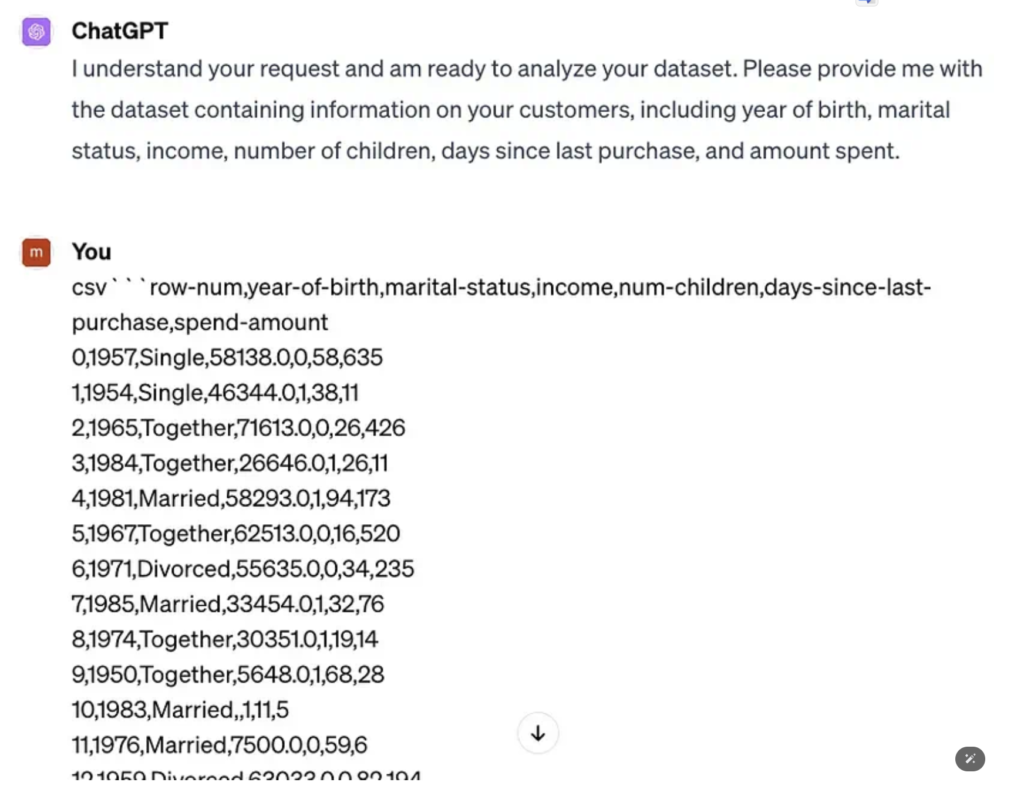
這個範例會使用一個常用的真實世界 Kaggle 資料集,該資料集是為客戶個性分析任務收集整理的,其中的任務目標是對客戶群進行細分,以便更好地了解客戶。
為了方便後面驗證 LLM 的分析結果,這裡只取一個子集,其中包含 50 行和最相關的列。之後,用於分析的資料集如下所示,其中每一行都代表一個客戶,而列則描述了客戶資訊:

假設你在該公司的宣傳團隊工作。你的任務使用這個客戶資訊資料集來指導行銷工作。這個任務分為兩步:第一步,使用資料集產生有意義的細分客戶群。第二步,針對每個細分群產生最好的行銷策略。現在,這個問題就成了模式發現(第一步)的實際業務問題,這也正是 LLM 擅長的能力。
下面針對這個任務草擬一個 prompt,這裡用到了 4 種提示工程技術(後面還有更多!):
- 將複雜任務分解為簡單步驟
- 索引每一步的中間輸出
- 設定 LLM 的回應的格式
- 將指令與資料集分離開
System Prompt:I want you to act as a data scientist to analyze datasets. Do not make up information that is not in the dataset. For each analysis I ask for, provide me with the exact and definitive answer and do not provide me with code or instructions to do the analysis on other platforms.
Prompt:# CONTEXT #I sell wine. I have a dataset of information on my customers: [year of birth, marital status, income, number of children, days since last purchase, amount spent].#############
# OBJECTIVE #I want you use the dataset to cluster my customers into groups and then give me ideas on how to target my marketing efforts towards each group. Use this step-by-step process and do not use code:
1. CLUSTERS: Use the columns of the dataset to cluster the rows of the dataset, such that customers within the same cluster have similar column values while customers in different clusters have distinctly different column values. Ensure that each row only belongs to 1 cluster.
For each cluster found,2. CLUSTER_INFORMATION: Describe the cluster in terms of the dataset columns.3. CLUSTER_NAME: Interpret [CLUSTER_INFORMATION] to obtain a short name for the customer group in this cluster.
4. MARKETING_IDEAS: Generate ideas to market my product to this customer group.5. RATIONALE: Explain why [MARKETING_IDEAS] is relevant and effective for this customer group.#############
# STYLE #Business analytics report############## TONE #Professional, technical#############
# AUDIENCE #My business partners. Convince them that your marketing strategy is well thought-out and fully backed by data.#############
# RESPONSE: MARKDOWN REPORT #<For each cluster in [CLUSTERS]>— Customer Group: [CLUSTER_NAME]— Profile: [CLUSTER_INFORMATION]— Marketing Ideas: [MARKETING_IDEAS]— Rationale: [RATIONALE]
<Annex>Give a table of the list of row numbers belonging to each cluster, in order to back up your analysis. Use these table headers: [[CLUSTER_NAME], List of Rows].#############
# START ANALYSIS #If you understand, ask me for my dataset.
GPT-4 的回覆如下,我們繼續以 CSV 字串的形式向其傳遞資料集。
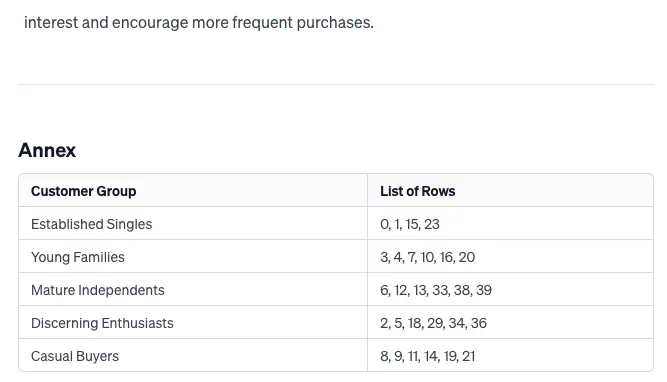
之後,GPT-4 以我們要求的 markdown 報告格式回覆其分析結果

驗證 LLM 的分析結果
為了簡單起見,我們將選取 LLM 產生的 2 個客戶群來進行驗證,即年輕家庭(Young Families)和高品味愛好者(Discerning Enthusiasts)。
年輕家庭
LLM 分析出的人群畫像:1980 年後出生,已婚或同居,中低收入,頻繁進行小額購買。
被 LLM 聚集到這一分組的行:3, 4, 7, 10, 16, 20
深入研究這些資料集,這些行的完整資料為:
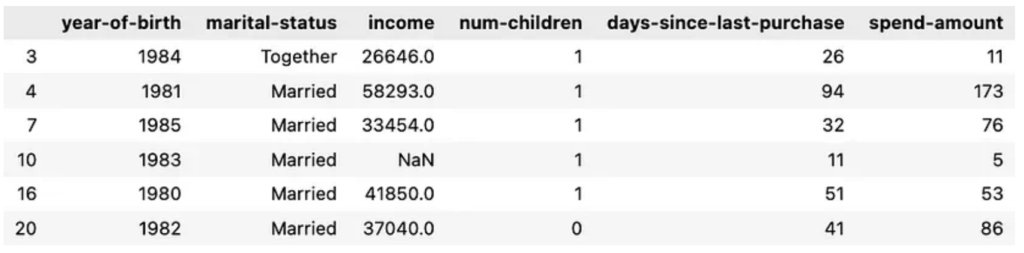
其剛好對應於 LLM 辨識出的人群畫像。它甚至能在不事先預處理的情況下聚類空值行!
高品味愛好者
LLM 分析出的人群畫像:年輕範圍廣,任意婚姻狀況,高收入,不同的子女狀況,購物支出高。
被 LLM 聚集到這一分組的行:2, 5, 18, 29, 34, 36
深入研究這些資料集,這些行的完整資料為:
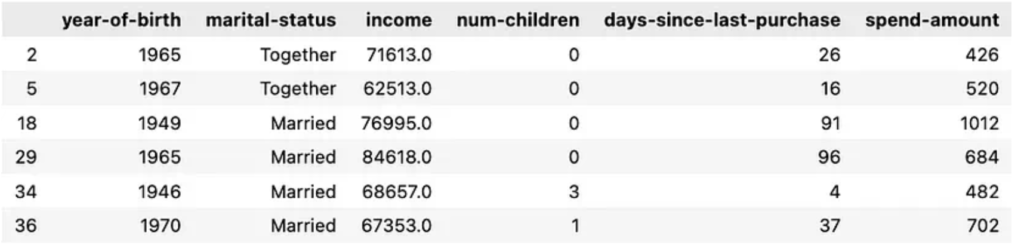
這同樣與 LLM 辨識出的人群畫像非常符合!
這個例子彰顯了 LLM 發現模式的能力,其能從多維度的資料集中解讀和提煉出有意義的見解,這能確保其分析深深植根於資料集的事實真相。
如果使用 ChatGPT 的進階資料分析插件呢?
為了完整比較,我使用相同的 prompt 嘗試了相同的任務,但是讓 ChatGPT 使用程式碼執行分析,這會啟動其進階資料分析外掛程式。這裡的想法是讓插件直接在資料集上運行 k – 均值聚類等聚類演算法的程式碼,從而得到每個客戶群,之後再合成每個聚類的人群畫像,以提供行銷策略。
但是,多次嘗試都得到了以下報錯訊息,並沒有輸出,儘管這個資料集只有 50 行:

目前而言,使用進階資料分析外掛程式只能執行更簡單的資料集任務,例如計算描述性統計資料或建立圖表,但需要演算法的更進階任務有時可能會遭遇報錯,無法得到輸出結果,原因可能是計算限制等問題。
那麼 LLM 適合在什麼時候用來分析資料集呢?
答案是取決於分析的類型。
對於需要精準數學計算或基於規則的複雜處理的任務,常規的程式設計方法仍然更優。
對於基於模式識別的任務,使用常規的程式設計和演算法方法可能很困難且非常耗時。而 LLM 擅長這些任務,甚至還能提供額外的輸出,例如用於支撐其分析結果的附加說明,以 markdown 格式編寫完整的分析報告。
最終,決定是否使用 LLM,取決於當前任務的性質以及 LLM 的模式識別能力與傳統程式設計技術提供的精確性和針對性之間的權衡。
現在回到提示工程!
本章節最後,我們回到用於生成資料集分析的 prompt,分解其中使用的關鍵性提示工程技術:
Prompt:# CONTEXT #I sell wine. I have a dataset of information on my customers: [year of birth, marital status, income, number of children, days since last purchase, amount spent].#############
# OBJECTIVE #I want you use the dataset to cluster my customers into groups and then give me ideas on how to target my marketing efforts towards each group. Use this step-by-step process and do not use code:
1. CLUSTERS: Use the columns of the dataset to cluster the rows of the dataset, such that customers within the same cluster have similar column values while customers in different clusters have distinctly different column values. Ensure that each row only belongs to 1 cluster.
For each cluster found,2. CLUSTER_INFORMATION: Describe the cluster in terms of the dataset columns.3. CLUSTER_NAME: Interpret [CLUSTER_INFORMATION] to obtain a short name for the customer group in this cluster.
4. MARKETING_IDEAS: Generate ideas to market my product to this customer group.5. RATIONALE: Explain why [MARKETING_IDEAS] is relevant and effective for this customer group.#############
# STYLE #Business analytics report############## TONE #Professional, technical#############
# AUDIENCE #My business partners. Convince them that your marketing strategy is well thought-out and fully backed by data.#############
# RESPONSE: MARKDOWN REPORT #<For each cluster in [CLUSTERS]>— Customer Group: [CLUSTER_NAME]— Profile: [CLUSTER_INFORMATION]— Marketing Ideas: [MARKETING_IDEAS]— Rationale: [RATIONALE]
<Annex>Give a table of the list of row numbers belonging to each cluster, in order to back up your analysis. Use these table headers: [[CLUSTER_NAME], List of Rows].############## START ANALYSIS #If you understand, ask me for my dataset.
AI 指令教學技術 1:將複雜任務分解為簡單步驟
LLM 擅於執行簡單任務,並不很擅長複雜任務。因此,對於這樣的複雜任務,一個很好的做法是將其分解成簡單的逐步指示,以便 LLM 遵從。這裡的想法是為 LLM 提供你希望採取的步驟。
在這個案例中,給出步驟的方式為:
Use this step-by-step process and do not use code:
1. CLUSTERS: Use the columns of the dataset to cluster the rows of the dataset, such that customers within the same cluster have similar column values while customers in different clusters have distinctly different column values. Ensure that each row only belongs to 1 cluster.
For each cluster found,2. CLUSTER_INFORMATION: Describe the cluster in terms of the dataset columns.3. CLUSTER_NAME: Interpret [CLUSTER_INFORMATION] to obtain a short name for the customer group in this cluster.
4. MARKETING_IDEAS: Generate ideas to market my product to this customer group.5. RATIONALE: Explain why [MARKETING_IDEAS] is relevant and effective for this customer group.
這裡並沒有直接簡單地給 LLM 提供一個整體的任務描述,例如「將客戶聚類成不同的客戶群,然後針對每個客戶群給出行銷見解。」
透過使用逐步指示,LLM 更有可能給出正確結果。
AI 指令教學技術 2:索引每一步的中間輸出
在為 LLM 提供逐步過程時,我們給出了每一步的中間輸出結果,其中用的大寫變數名稱指代,即 CLUSTERS、CLUSTER_INFORMATION、CLUSTER_NAME、MARKETING_IDEAS 和 RATIONALE。
使用大寫可以將這些變數名與指令主體區分開。然後,可以透過加方括號的形式 [變數名稱] 來索引這些中間輸出。
AI 指令教學技術 3:設定 LLM 的回應的格式
這裡我們要求輸出 markdown 報告格式,能美化 LLM 的回應結果。在這裡,中間輸出的變數名稱再次派上用場,可以更方便地指定報告的結構。
# RESPONSE: MARKDOWN REPORT #<For each cluster in [CLUSTERS]>— Customer Group: [CLUSTER_NAME]— Profile: [CLUSTER_INFORMATION]— Marketing Ideas: [MARKETING_IDEAS]— Rationale: [RATIONALE]
<Annex>Give a table of the list of row numbers belonging to each cluster, in order to back up your analysis. Use these table headers: [[CLUSTER_NAME], List of Rows].
事實上,你之後也可以讓 ChatGPT 提供可下載的報告文件,讓其直接完成你的最終報告。

AI 指令教學技術 4:將任務指令與資料集分離開
可以看到,我們從未在第一個 prompt 中向 LLM 提供資料集。相反,該 prompt 只給了資料集分析的任務指令,最後再加上了以下內容:
START ANALYSIS
If you understand, ask me for my dataset.
然後,ChatGPT 回答它理解了,然後我們再在下一個 prompt 中以 CSV 字串的形式將資料集傳遞給它。
但為什麼要將任務指令與資料集分離開?
這樣做有助於 LLM 清晰地理解每一部分,降低遺漏資訊的可能性;尤其是當任務更複雜時,例如例子中這個指令較長的任務。你可能經歷過 LLM「意外遺忘」長 prompt 中某個特定指令的情況,舉個例子,如果你讓 LLM 給出 100 字的回應,但其回饋的結果卻長得多。而如果讓 LLM 先接收指令,然後再接收指令處理的資料集,就能讓 LLM 先消化其應當做的事情,之後再基於後面提供的資料集來執行它。
請注意,這種指令與資料集分離的操作僅適用於有對話記憶的聊天式 LLM,不適用於沒有對話記憶的任務完成式 LLM。